HardGPT
GPT on a $1 chip in 32KB of RAM. A character-level transformer that runs entirely on a Cortex-M0+ with no FPU.
TL;DR
Squeezed a 3-layer character-level GPT into 125KB of flash and 29KB of SRAM on a TI MSPM0G3507. Custom PCB, int8 weights and KV cache, Quake inverse-square-root, Schraudolph softmax. Types fake-Shakespeare on the LCD one character at a time.
the obsession
My embedded systems class at Rice handed us a TI MSPM0G3507. Cortex-M0+ at 80MHz, 128KB of flash, 32KB of SRAM, no floating point unit, about a dollar in bulk. Most people in the class tried to use it to blink LEDs or drive a motor.
But I wanted to run a transformer on it.
An actual GPT, trained from scratch, quantized to int8, ported to a hand-written C inference engine that fits inside 128KB of flash. Three layers, four heads, 48-dim embeddings. Every matmul, layernorm, softmax, and GELU written by hand and budgeted to the byte.
the problem
Float32 weights would be 332KB. The chip has 128KB of flash. Float activations and KV cache want 70KB of
SRAM. The chip has 32KB. Every sqrtf and expf compiles to a software emulation
routine that takes thousands of cycles. Nothing fits and nothing is fast. The whole project is figuring
out what to cut and how to cut it without the model falling apart.
the board
The final build is a custom two-layer PCB with the MSPM0, an AMS1117 regulator, a 16x2 LCD over I2C, three buttons, three LEDs, a buzzer, and a pot that controls sampling temperature. Power it over USB-C, press generate, it starts typing. Once you flash the firmware the board runs on its own.

The fully assembled HardGPT
An AMS1117 LDO drops USB or battery voltage to 3.3V. Three tactile buttons sit between GPIO and ground with the chip's internal pull-ups doing the work. Three indicator LEDs through 220Ω resistors. An active buzzer switched through a 2N3904 NPN with a 1N4148 flyback diode. The HD44780 LCD talks to the chip over I2C through a PCF8574 expander on the back of the module. A 10kΩ pot wired as a voltage divider feeds a 12-bit ADC channel and maps linearly onto the softmax temperature.
the pipeline
There's a Python side and a C side. The Python side trains the model in nanoGPT, quantizes the weights to
int8, and dumps everything into a single weights.h file. The C side includes that header
and runs inference. The two sides never interact at runtime.
Training happens on a laptop. We forked Karpathy's nanoGPT, configured it tiny (3 layers, 4 heads, dim
48, context 48, vocab 65 characters), and trained on tiny-shakespeare for 30k steps. A separate script
applies symmetric per-output-channel int8 quantization to every weight matrix and writes out the C
header. That header is a bunch of const int8_t arrays and const float scale
arrays. The entire interface between Python and firmware.
The firmware includes weights.h directly, implements the transformer forward pass against
those int8 arrays, and drives all the I/O. The KV cache also lives in int8 inside SRAM.
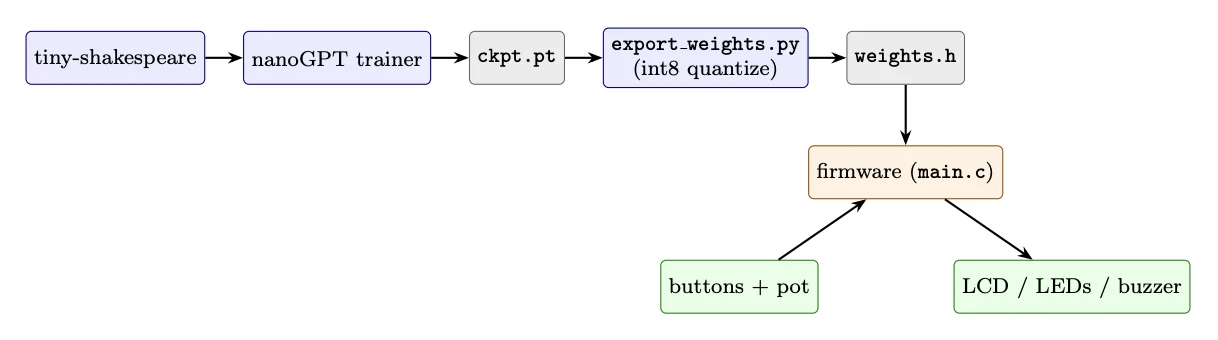
Blue is offline Python. Orange is on-chip firmware. Green is real-world I/O. Grey is generated artifacts.
| Parameter | Value |
|---|---|
| Layers / heads / embedding dim | 3 / 4 / 48 |
| Head dimension | 12 |
| Context window | 48 tokens |
| Vocabulary | 65 characters |
| Weight format | int8, per-output-channel scales |
| KV cache format | int8, per-vector scales |
| Total parameters | ~90K |
| Flash usage | 125.2KB of 128KB (97.8%) |
| SRAM usage | 29.4KB of 32KB (91.9%) |
Shipped model configuration
One extra transformer layer would not have fit.
where the bytes go
Storing weights in float32 costs 332KB. Int8 with one float scale per output row drops that to 86KB,
which fits with room for code. SRAM was tighter. Float activations and KV cache wanted 70KB. Int8 brings
that to about 18KB. The KV cache alone is
3 layers × 48 tokens × 2 (K and V) × 48 dim = 13.5KB, which is why we
quantized it too. Every position in the cache stores its own K scale and V scale so that activation
drift across positions doesn't blow up the quantization range.
the forward pass
Each token costs one full forward pass. Embedding lookup, three transformer layers (layernorm, QKV projection, cache the K and V, attention, layernorm, MLP with GELU), final layernorm, project against the tied embedding for logits. Read the temperature off the pot, softmax, sample a character, write it to the LCD. Slide the KV cache window if we've hit 48 tokens.
The architecture is a straight nanoGPT block. Pre-LayerNorm, multi-head causal attention, 4x MLP with GELU, weight tying between the input embedding and the output projection. Nothing exotic. The work is making it survive int8 on a chip with no FPU.
The KV cache is what makes per-character generation cheap. Without it we'd rerun attention over every previous token at every step. With it, we project K and V once per token, store them, and attend over history.
one function does almost all the work
A single int8-by-int8 matvec handles QKV projection, the attention output, and both MLP matmuls. The
inner loop is two int8 loads and one multiply-accumulate. We accumulate in int32 and touch a
float only once per output row to apply the per-channel scale.
static void matvec_i8i8_pc(
const int8_t *W, const float *W_scales,
const int8_t *in, float in_scale,
float *out,
int out_dim, int in_dim)
{
for (int o = 0; o < out_dim; o++) {
int32_t acc = 0;
const int8_t *row = W + o * in_dim;
for (int i = 0; i < in_dim; i++) {
acc += (int32_t)row[i] * (int32_t)in[i];
}
out[o] = (float)acc * W_scales[o] * in_scale;
}
}Per-output-channel scales matter here. A single per-tensor scale loses too much precision when some output rows have weights in the ±2.0 range and others sit around ±0.05. Per-channel lets each row use the full int8 dynamic range independently. We measured a 4.3x spread between the smallest and largest row scales in the embedding matrix alone.
bit-hack floats
Once the matmuls were int8, the remaining floating-point work was layernorm, softmax, and GELU. Each
sqrtf, expf, and tanhf compiled to a software emulation routine
eating thousands of cycles per call. We replaced each one with an integer bit-hack.
Quake's 0x5f3759df for inverse square root in layernorm and the attention scale.
Schraudolph's IEEE-754 trick for exp in softmax. A Padé approximation for tanh in GELU. Each one
replaced a library call taking thousands of cycles with a few integer operations. Together they sped up
the forward pass by roughly 10x.
static float fast_invsqrt(float x) {
float xhalf = 0.5f * x;
int32_t i;
memcpy(&i, &x, 4);
i = 0x5f3759df - (i >> 1);
memcpy(&x, &i, 4);
x *= (1.5f - xhalf * x * x);
return x;
}The errors are small enough to disappear. The invsqrt is within ~1%. Schraudolph's exp has ~5% relative error, but softmax normalizes, so constant-factor error in individual exponentials mostly cancels. The Padé tanh is within 1.2% in the range GELU cares about and clipped to ±1 outside.
what it generates
The model generates recognizable fake Shakespeare. Real character names (LEONTES, KING RICHARD), proper play structure with colons and line breaks, plausible English word fragments. At val loss 1.83 it can hold a phrase together for four or five words before drifting. That's about right for 90K parameters trained on 1MB of text.
LEONTES:
To shall you, he but me was horse by loothe e sprest
shate before trend..Turning the temperature pot changes the output live. Low temperature gives you repetitive but coherent text. High temperature gives you creative chaos. Around 0.8 it finds a sweet spot.
HardGPT
Built for ELEC 327 at Rice University by Hemesh Chadalavada and Arda Inegol